Spring Kafka源码阅读小记之消费者
Spring Kafka在原生kafka客户端的基础上进行了封装,提供了非常方便的配置方法和使用方法,不管是生产者或是消费者,都能简单几行代码搞定。非常的Spring。前几天遇到同一消费者组下需要多实例集群中仅单实例消费的需求,由于初次接触Spring Kafka这个框架,一时之间没想到什么好办法,所以索性翻翻源码,增进一下对它的了解。然后顺便再找一找解决方法。
基于Spring Kafka 2.2.12.RELEASE
1. 如何定义kafka消费者
在Spring Kafka框架下定义消费者相当简单分别有两种模式:
- 类级别注解定义,相关注解:
@KafkaListener、@KafkaListeners、@KafkaHandler - 方法级别注解定义,相关注解:
@KafkaListener、@KafkaListeners
自动配置的代码可以参考官方教程,此处略。
其中,@KafkaListeners可以由多个@KafkaListener替代。
类级别注解定义示例:
@Slf4j
@Component
@KafkaListener(topics = "test")
public class DemoClassConsumer {
@KafkaHandler(isDefault = true)
public void handle(String payload) {
log.info("default handle - receive data: {}", payload);
}
@KafkaHandler
public void handleString(String payload) {
log.info("string handle - receive data: {}", payload);
}
}
@Component注解是必加的,因为只有Spring的Bean才会触发Kafka Spring的Bean后处理方法。@KafkaListener声明消费的topic等信息,该注解还包含许多其他非常有用的属性。@KafkaHandler声明处理收到消息的方法,它只有一个属性isDefault。可以使用@KafkaHandler声明多个方法,每一个方法的入参类型必须不一样,Spring Kafka将依靠收到消息的类型,来判断应该用哪个方法处理。当isDefault = true时,指定该方法为所有类型都匹配不到时的默认方法,类似switch的default,此时入参可以与其它方法入参类型相同。
方法级别的注解定义更加简单:
@Slf4j
@Component
public class DemoConsumer {
@KafkaListener(topics = "test")
public void handle(String message) {
log.info("receive message: {}", message);
}
}
作为两个消费者的Demo,上面的代码已经至少可以“跑起来了”。
2. 多实例部署
假设有一个新问题,类似“多实例下仅单实例消费,且在同一个消费者组”之类的问题时,上面的理解程度明显就不够用了。
“对一个Topic,同一个消费者组下服务的多个实例中只能有一个实例消费”,能不能用多个消费者组实现?技术上可以,比如直接在@KafkaListener中用SpEL表达式定义groupId,让其每一个实例都拥有一个不同的消费者组,这样一个消费者组下就只有一个消费者了,貌似问题解决了?
单纯咬文嚼字确实好像问题解决了,因为保证了同一个groupId下有且仅有一个消费者。但是,再想想,能不能保证最基本的,不重复消费消息,不丢消息(kafka中的某些消息可能消费不到)?
明显不能,多个groupId就已经注定了所有组下面都会收到相同的消息,不管如何定义消费策略,earlest, latest,都无济于事,如果硬要手动同步不同组下的offset,我想带来的新问题会比解决这个问题更复杂。
有没有简单的办法?
肯定有啊,分布式锁 + 动态消费者,抢到锁的实例才能开启消费者。
分布式锁好办,引入redisson,单线程持续抢锁,配置+代码,不超过50行,包括空行。
那如何动态开启消费者?
3. 动态消费者
众所周知,Kafka的消费模式为客户端不断的拉消息。这里说的动态,指可以动态开启和关闭这个消费者,不是在消息处理方法中判断是否该消费,这样的实现太难看,而是要关闭拉这个过程,又或者,可以拉消息,但是不能消费,不能提交offset,但是这样有可能把内存耗尽。
如果使用原生Kafka客户端来实现,当然可以,但是工作量可能会比较大,既然引入了Spring Kafka这个框架,那就要发挥这个框架的价值,框架能不能实现,如何实现?
框架当然能。
很简单的一个参数,请看:
KafkaListener(topics = "test-consumer", autoStartup = "false")
autoStartup表示是否在启动后自动开启消费者,否不就完事了,大家都先别消费,抢完锁再消费。
抢锁过程不在讨论范围。
假如其中的一个实例抢到锁了,怎么能打开它呢?请看:
@Slf4j
@Service
@AllArgsConstructor
public class ConsumerManager implements ApplicationRunner {
private KafkaListenerEndpointRegistry endpointRegistry;
@Override
public void run(ApplicationArguments args) throws Exception {
if (getDistributeLockSuccessfully()) {
endpointRegistry.start(); //此方法会将没运行的消费者全部打开
}
}
}
就是这么easy。
再来回归一下那两个基本问题会不会重复消费,会不会丢消息。
第一个问题,同一个消费者组,肯定不会。
第二个问题,绝大概率不会,依赖于具体配置和业务代码的实现。
针对第二个问题,看一看Spring Kafka拉取到消息后,是如何丢给KafkaListener们消费的。看一看KafkaMessageListenerContainer.invokeOnMessage(final ConsumerRecord<K, V> record, @SuppressWarnings(RAWTYPES) @Nullable Producer producer)的实现:
private void invokeOnMessage(final ConsumerRecord<K, V> record, @SuppressWarnings(RAWTYPES) @Nullable Producer producer) {
// (1)检查key和value是否是一个DeserializationException异常
// (2)如果key和value为空,判断其headers中是否包含Spring反序列化异常
// (3)调用实际的消息处理逻辑
doInvokeOnMessage(record);
// (4)commit offset
ackCurrent(record, producer);
}
是的,在(3)的时候,即实际的处理业务代码后,Spring Kafka才会帮你提交offset,而如果在(3)的时候,你抛了个异常,那是不是就不会提交了?是不是业务端只要处理失败后抛个异常出来就万事大吉啦?
非也,继续翻它的调用者:
private RuntimeException doInvokeRecordListener(final ConsumerRecord<K, V> record,@SuppressWarnings(RAW_TYPES) Producer producer,Iterator<ConsumerRecord<K, V>> iterator) {
try {
// (1)
invokeOnMessage(record, producer);
} catch (RuntimeException e) {
// (2)
if (this.containerProperties.isAckOnError() && !this.autoCommit && producer == null) {
ackCurrent(record);
}
// (3)各种异常处理balabala
...
}
return null;
}
很不幸,invokeOnMessage(record, producer)抛出的异常被捕获了,而且在满足某些条件的情况下,它仍然会帮你提交offset。so sad🐶。具体看看是什么条件isAckOnError(),autoCommit,producer,其中如果kafka消费时没有定义事务,那producer == null,autoCommit的值,取决于spirng配置中spring.kafka.consumer.enable-auto-commit 的值,默认为false。我去,后两个条件都满足了,继续看isAckOnError():
public boolean isAckOnError() {
return this.ackOnError &&
!(AckMode.MANUAL_IMMEDIATE.equals(this.ackMode)
||AckMode.MANUAL.equals(this.ackMode));
}
其中this.ackOnError默认为true,让整个方法返回false的唯一方法,是定义this.ackMode为MANUAL_IMMEDIATE或MANUAL,而其默认为BATCH,更加sad了🐶。
所以,如果配置不当,又没有事务保证,在业务逻辑处理异常后,比如要存个数据库结果没存进去还抛了个异常,这个时候就会丢数据 - kafka的数据已经消费了,却没有成功入库。
虽然Spring Kafka保证了大部分情况下的健壮,但是正确的配置和正确的业务逻辑处理也很重要。否则丢消息在所难免。
4. Ack模式与错误处理
Spring Kafka提供的ACK模式有以下几种:
| ACK模式 | 描述 |
|---|---|
| RECORD | 每条消息处理完后马上提交offset |
| BATCH | 下一次poll前,将全部提交上一次poll的消息,不管有没有真正消费到🤣 |
| TIME | 按时提交offset |
| COUNT | 按消息数提交 |
| COUNT_TIME | 即 TIME || COUNT 就提交 |
| MANUAL | 手动提交,批量模式 |
| MANUAL_IMMEDIATE | 手动马上提交 |
默认配置下,SpringKafka将使用自动提交,且Ack模式为BATCH,所以还是很容易丢消息。
默认配置的ErrorHandler,仅仅只是打印一下日志,但是Spring Kafka还提供了几个默认实现。
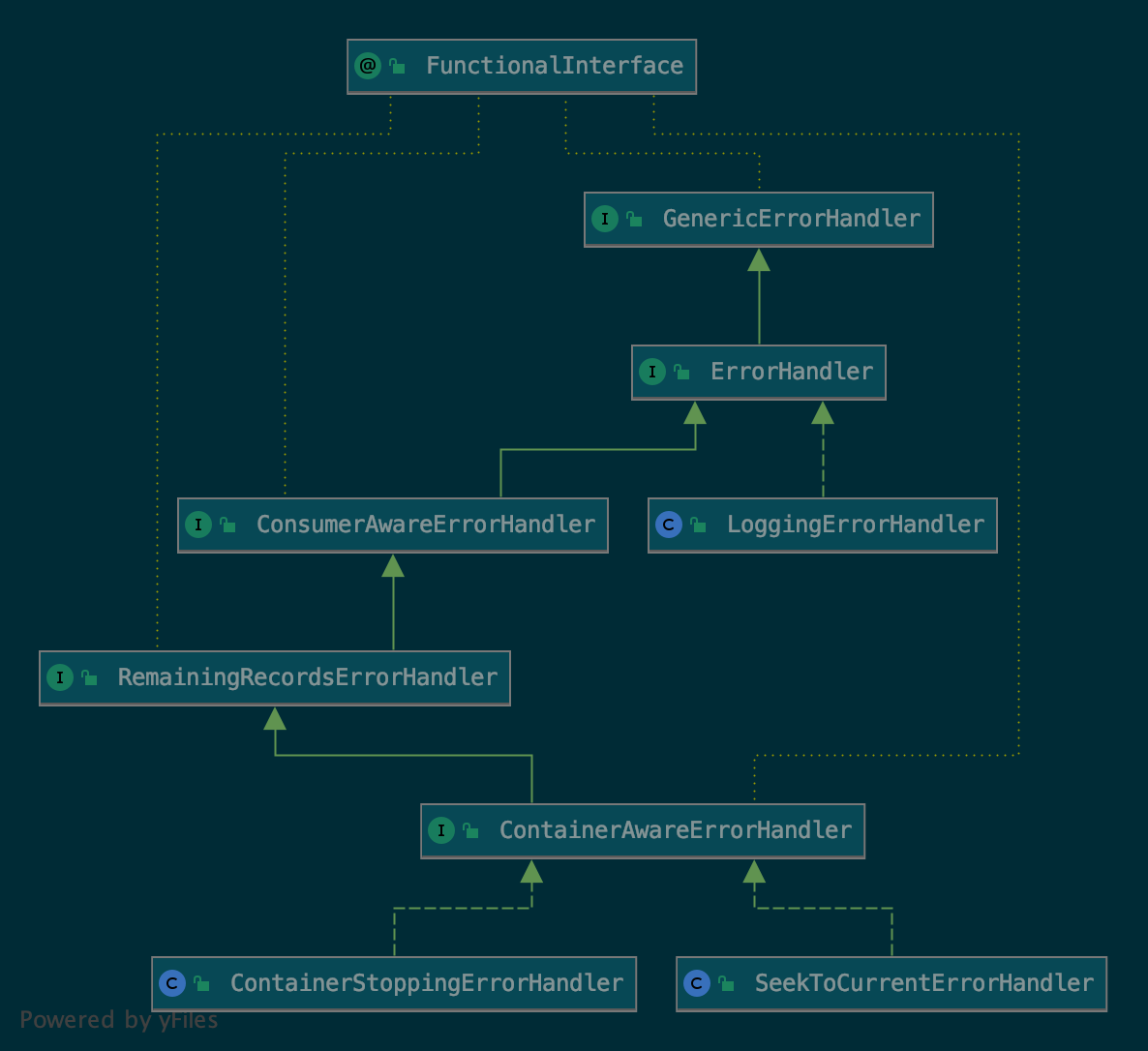
-
ContainerStoppingErrorHandler -
SeekToCurrentErrorHandler
这些实现必须声明为Bean才能注入到配置中。
5. Dive In Src
统筹兼顾一下,如上分析,配置+业务代码质量能显著影响Kafka消息的消费健壮性。主要在四个方面:
- 【T1】offset提交
- 【T2】异常处理
- 【T3】事务
为了更好的弄明白Spring Kafka是如何让这些配置影响消费者的,以及KafkaListener所标注的这些方法或者类如何才能更好的提交offset,再深入一点,不妨再从源码入手,从定义消费者的“始作俑者”,@KafkaListener开始,弄清楚,消费者是如何配置的,如何注入的,如何管理的,如何启动,如何停止,如何最后将消息传给实际处理方法,最后如何处理offset,如何处理异常的。
将问题分个类:
- 【Q1】Kafka消费者的生命周期管理
- 【Q2】Kafka消费者的异常处理
- 【Q3】Kafka事务 (单独开篇,此篇仅讨论无事务情况)
4.1 注解扫描
@EnableKafka将实际引入Kafka Spring的注解扫描配置。
该注解可以放置在主类上,或者其他@Configuration上,甚至可以不放,至于为啥可以不放,感兴趣的可以翻翻KafkaAutoConfiguration的源码。
开启Spring Kafka中@EnableKafka注解后,将触发KafkaBootstrapConfiguration自动配置,这配置干了啥呢?相当简单:
@Configuration
public class KafkaBootstrapConfiguration {
@SuppressWarnings("rawtypes")
@Bean(name = KafkaListenerConfigUtils.KAFKA_LISTENER_ANNOTATION_PROCESSOR_BEAN_NAME)
@Role(BeanDefinition.ROLE_INFRASTRUCTURE)
public KafkaListenerAnnotationBeanPostProcessor kafkaListenerAnnotationProcessor() {
return new KafkaListenerAnnotationBeanPostProcessor();
}
@Bean(name = KafkaListenerConfigUtils.KAFKA_LISTENER_ENDPOINT_REGISTRY_BEAN_NAME)
public KafkaListenerEndpointRegistry defaultKafkaListenerEndpointRegistry() {
return new KafkaListenerEndpointRegistry();
}
}
看起来确实相当简单呀,定义了两个Bean,KafkaListenerAnnotationBeanPostProcessor和KafkaListenerEndpointRegistry,通过源码上的文档,可以清楚的知道这两个Bean的作用。
KafkaListenerAnnotationBeanPostProcessor
/**
* Bean post-processor that registers methods annotated with {@link KafkaListener}
* to be invoked by a Kafka message listener container created under the covers
* by a {@link org.springframework.kafka.config.KafkaListenerContainerFactory}
* according to the parameters of the annotation.
*/
意思是,这是一个Bean后处理器,这个后处理器专门用来注册那些被@KafkaListener标注的方法(感觉文档里漏了一点,还有可能是类),这些方法将会被kafka消息监听容器所触发,而这些容器归于KafkaListenerContainerFactory管理。
KafkaListenerEndpointRegistry
/**
* Creates the necessary {@link MessageListenerContainer} instances for the
* registered {@linkplain KafkaListenerEndpoint endpoints}. Also manages the
* lifecycle of the listener containers, in particular within the lifecycle
* of the application context.
*
* <p>Contrary to {@link MessageListenerContainer}s created manually, listener
* containers managed by registry are not beans in the application context and
* are not candidates for autowiring. Use {@link #getListenerContainers()} if
* you need to access this registry's listener containers for management purposes.
* If you need to access to a specific message listener container, use
* {@link #getListenerContainer(String)} with the id of the endpoint.
*/
哎呀妈呀,全是阅读理解🤣。
这两段话的大概意思是,这个类用于为那些已经注册到这个类里的endpoints创建必要的Kafka消息监听容器(是不是和上面那个Bean有那么点关系了),同时也将管理这些Kafka消息监听容器的生命周期。这些被管理的消息监听容器不是以Bean的形式存在于应用上下文中,所以是无法被自动注入的,如果需要引用这些消息监听容器,需要用到此类的getListenerContainers()方法。
两个类分别解决了Q1和Q2,先看Q1。
KafkaListenerAnnotationBeanPostProcessor实现了4个Spring相关的接口,其中最重要的有两个,一个是SmartInitializingSingleton,另一个是BeanPostProcessor。前者用于提前实现单例Bean的初始化,后者用于增强Bean。
在分析它们的源码前,有一件事情必须搞清楚,Spring提供的这些钩子,什么时候被调用,谁先调用谁后调用?如果无法理解他们的前后关系,理解上将出现巨大的偏差。此处不做过多探讨。
如果没耐心查资料,直接断点,此处有三个方法需要搞清楚调用顺序,分别是:
SmartInitializingSingleton.afterSingletonsInstantiated()BeanPostProcessor.postProcessBeforeInitialization()BeanPostProcessor.postProcessAfterInitialization()
很明显BeanPostProcessor的先后顺序显而易见。通过断点发现:postProcessBeforeInitialization() -> postProcessAfterInitialization() -> afterSingletonsInstantiated()。(IDEA真香
所以先看实现了BeanPostProcessor接口的方法:
@Override
public Object postProcessAfterInitialization(final Object bean, final String beanName) throws BeansException {
//一个巨大的判断
if (!this.nonAnnotatedClasses.contains(bean.getClass())) {
// 获取原始Bean类型,以防被代理
Class<?> targetClass = AopUtils.getTargetClass(bean);
//开始干实事了,找类级别的@KafkaListener注解
Collection<KafkaListener> classLevelListeners = findListenerAnnotations(targetClass);
final boolean hasClassLevelListeners = classLevelListeners.size() > 0;
final List<Method> multiMethods = new ArrayList<>();
//又干了件实事,找方法级别的@KafkaListener注解
Map<Method, Set<KafkaListener>> annotatedMethods = MethodIntrospector.selectMethods(targetClass,(MethodIntrospector.MetadataLookup<Set<KafkaListener>>) method -> {
Set<KafkaListener> listenerMethods = findListenerAnnotations(method);
return (!listenerMethods.isEmpty() ? listenerMethods : null);
});
//如果有类级别的注解,则还需要确定找到其中的@KafkaHandler注解,是不是和第一章的使用方法对上了
if (hasClassLevelListeners) {
Set<Method> methodsWithHandler = MethodIntrospector.selectMethods(targetClass,(ReflectionUtils.MethodFilter) method -> AnnotationUtils.findAnnotation(method, KafkaHandler.class) != null);
multiMethods.addAll(methodsWithHandler);
}
if (annotatedMethods.isEmpty()) {
this.nonAnnotatedClasses.add(bean.getClass());
if (this.logger.isTraceEnabled()) {
this.logger.trace("No @KafkaListener annotations found on bean type: " + bean.getClass());
}
} else { //如果找到了方法级别的注解,丢给别人再去包装
for (Map.Entry<Method, Set<KafkaListener>> entry : annotatedMethods.entrySet()) {
Method method = entry.getKey();
for (KafkaListener listener : entry.getValue()) {
//(1)包装方法级别的消费者
processKafkaListener(listener, method, bean, beanName);
}
}
//如果有类级别的注解,也丢给别人再去包装。
if (hasClassLevelListeners) {
//(2)包装类级别的消费则
processMultiMethodListeners(classLevelListeners, multiMethods, bean, beanName);
}
}
return bean;
}
这实现就跟写大纲似的,在其他bean完成初始化后,就会调用这个后处理方法,这个后处理方法会找到所有被@KafkaListener标注的方法,以及所有被@KafkaListener标注的类中的@KafkaHandler修饰的方法,然后继续对他们进行包装。
(1)找到方法级别的消费者后,processKafkaListener将该方法包装到MethodKafkaListenerEndpoint类实例化的endpoint中,之后从注解中将各个参数解析出来赋给endpoint,最后,该endpoint会被注册到KafkaListenerEndpointRegistrarBean中,调用的是其registerEndpoint()方法。这是一个KafkaListenerEndpointRegistry的帮助类。当endpoint注册到Registrar中的时候发生了什么呢?继续看源码:
public void registerEndpoint(KafkaListenerEndpoint endpoint, KafkaListenerContainerFactory<?> factory) {
// 参数校验
...
// 打包endpoint和其对应的工厂,方便存储
KafkaListenerEndpointDescriptor descriptor = new KafkaListenerEndpointDescriptor(endpoint, factory);
// 同步一下ArrayList,防止被同时操作
synchronized (this.endpointDescriptors) {
if (this.startImmediately) {
this.endpointRegistry.registerListenerContainer(descriptor.endpoint, resolveContainerFactory(descriptor), true);
} else {
this.endpointDescriptors.add(descriptor);
}
}
}
主要逻辑在同步代码块中,this.startImmediately的值默认为false,之后会改变,后文会讲到。所以此时它只是暂时把endpoint再包装一次放入一个列表中,KafkaListenerEndpointDescriptor这个类完全就是个只有两个属性的结构体,没有啥特殊的方法。如果是Spring Kafka完成了整个启动过程之后,再有业务来调用这个注册方法时,就会直接注册到endpointRegistry中,并立即启动。
(2)找到类级别的消费者后,processMultiMethodListeners将这些方法包装到MultiMethodKafkaListenerEndpoint类实例化的endpoint中,之后的处理方式就和(1)一模一样了。
到此为止,Kafka消费者的初始化(后处理)基本完成。接下来,Spring对KafkaListenerAnnotationBeanPostProcessor提供的最后一个钩子将发挥作用:afterSingletonsInstantiated()。
继续看看它都干了些啥:
@Override
public void afterSingletonsInstantiated() {
// 设置一些东西
...
// 为某个属性设置EndpointRegistry,眼熟吧
if (this.registrar.getEndpointRegistry() == null) {
if (this.endpointRegistry == null) {
Assert.state(this.beanFactory != null,
"BeanFactory must be set to find endpoint registry by bean name");
this.endpointRegistry = this.beanFactory.getBean(KafkaListenerConfigUtils.KAFKA_LISTENER_ENDPOINT_REGISTRY_BEAN_NAME,KafkaListenerEndpointRegistry.class);
}
// 实际上这个endpointRegistry的Bean就是在自动配置中声明的那个
this.registrar.setEndpointRegistry(this.endpointRegistry);
}
// Actually register all listeners
this.registrar.afterPropertiesSet();
}
这个钩子为registrar这个帮助类的实例设置了一些必要的属性值,同时将endpointRegistry也注入了进去,最后再调用一个当所有属性都准备好后的方法afterPropertiesSet():
@Override
public void afterPropertiesSet() {
registerAllEndpoints();
}
protected void registerAllEndpoints() {
synchronized (this.endpointDescriptors) {
for (KafkaListenerEndpointDescriptor descriptor : this.endpointDescriptors) {
this.endpointRegistry.registerListenerContainer( descriptor.endpoint, resolveContainerFactory(descriptor));
}
this.startImmediately = true; // trigger immediate startup
}
}
第二个方法是不是有点眼熟,endpoint注册的时候也有类似的过程,只是现在这个方法把所有的descriptor全部取了出来并且立即注册到了endpointRegistry中,最后将startImmediately属性设置为了true。
现在BeanPostProcessor的整个过程都串起来了,并且打通了一个通往endpointRegistry的桥梁,通过这个桥梁,KafkaListenerAnnotationBeanPostProcessor将包装好的endpoints的管理权移交给了KafkaListenerEndpointRegistry,到此Spring Kafka并没有将业务逻辑和Kafka消费者真正关联起来,而仅仅是对业务逻辑进行了一个包装。
4.2 初始化
先看看”那座桥梁“到底干了啥:KafkaListenerEndpointRegistry.registerListenerContainer():
public void registerListenerContainer(KafkaListenerEndpoint endpoint, KafkaListenerContainerFactory<?> factory) {
registerListenerContainer(endpoint, factory, false);
}
public void registerListenerContainer(KafkaListenerEndpoint endpoint, KafkaListenerContainerFactory<?> factory, boolean startImmediately) {
// 参数校验
...
// 串一下
synchronized (this.listenerContainers) {
Assert.state(!this.listenerContainers.containsKey(id), "Another endpoint is already registered with id '" + id + "'");
//(1)包装之旅还没有结束...
MessageListenerContainer container = createListenerContainer(endpoint, factory);
this.listenerContainers.put(id, container);
if (startImmediately) {
startIfNecessary(container);
}
}
}
有一个很重要的参数startImmediately为false,这表明,整个”系统“仍然在初始化的过程。(1)阶段将endpoint再次包装成了一个MessageListenerContainer,这玩意是个接口,所以得具体进createListenerContainer()方法看看其实现类。在开始了解MessageListenerConatiner的封装过程前,有一个参数的来历需要标明一下:(1)中的factory参数。实际上向上回溯,该factory在BeanPostProcessor中被引入,依据为KafkaListener.containerFactory()属性,该属性可以定义工厂类的名字,默认为在KafkaAnnotationDrivenConfiguration中定义的一个并行消费者工厂:ConcurrentKafkaListenerContainerFactory,此处不展开,有兴趣可以看看源码,这个类包含了从Spring配置文件中获取的对Kafka消费者的具体配置,比如Message Converter、Error Handler、Transaction Manager等等,这个类将帮助(1)来包装endpoint。
工厂类将把消费者的公共配置参数结合注解的参数,一并初始化到MessageListenerContainer中,这样,它才拥有了完整的和kafka消费者相关的配置。
至此,所有Spring Kafka的相关配置参数的初始化完成,接下来,就要将这些方法和配置,和原生KafkaConsumer结合起来,实际上就是调用原生Kafka客户端来进行消费操作了。
4.3 运行消费者
在了解Spring Kafka如何创建原生的KafkaConsumer之前,先看看KafkaAutoConfiguration定义的一个和消费者相关的Bean。
- kafkaConsumerFactory -
DefaultKafkaConsumerFactory
又是一个工厂,真是无处不在的工厂呀。
很明显,这个Bean是用来生产消费者的(KafkaConsumer,这货是原生的kafka消费者,和Spring Kafka没啥关系),这个Bean在包装ContainerFactory生产Container的时候被初始化进去了,所以,每一个Container都有能力生产消费者。之所以让Container有能力生产消费者,和其注解提供的concurrency能力相关,以及多topic,多partitions消费相关。
姑且可以理解为一个@KafkaListener就代表了一个Container。
那如何初始化消费者,以及如何启动消费的呢?
KafkaListenerEndpointRegistry 实现了 SmartLifecycle 接口,所以,启动方法交由Spring来负责调用,即 SmartLifecycle.start() 开始,经过层层调用,实际上最关键的启动方法为ConcurrentMessageListenerContainer.doStart()。来,咱瞅一瞅
@Override
protected void doStart() {
// 参数校验和设置
...
for (int i = 0; i < this.concurrency; i++) {
//(1)根据concurrency数量,每一次循环又单独初始化一个container
KafkaMessageListenerContainer<K, V> container;
...
container.start();
this.containers.add(container);
}
}
(1)根据注解中concurrency配置的数量,初始化对应数量的单Container,这个单Container和其本身是不一样的哦,如果将ConcurrentMessageListenerContainer和@KafkaListener一一对应,那KafkaMessageListenerContainer 就可以理解为和(topic,partition)一一对应了,毕竟,虽然注解中定义了多个topics或者多个partitions,但是实际上消费的时候,他们肯定都是分开拉取消息消费的。最后会调用container.start()。继续看:
protected void doStart() {
// 校验参数之类的
...
// Runnable
this.listenerConsumer = new ListenerConsumer(listener, listenerType);
// 另起线程执行了
this.listenerConsumerFuture = containerProperties
.getConsumerTaskExecutor()
.submitListenable(this.listenerConsumer);
}
很明显,重点在ListenerConsumer类上,该类实现了两个接口:
-
ConsumerSeekCallback -
SchedulingAwareRunnable
第一个接口的作用在于可自定义消费的起点,第二个接口有点意思,它比Runnable就多一个isLongLived()接口,用于告诉WorkManager,这是个长跑线程,它不会自己停止。更具体的,可以看一看参考中第三个链接,有比较详细的描述。
public void run() {
//定义消费起点
...
// 持续拉取和消费
while (isRunning()) {
...
pollAndInvoke();
...
}
...
}
protected void pollAndInvoke() {
// 提交offset ...
// 检查是否需要重新定义消费起点 ...
// 检查是否被暂停 ...
// 拉取消息
ConsumerRecords<K, V> records = this.consumer.poll(this.pollTimeout);
// 消费消息
invokeListener(records);
//...
}
注释已经把过程抽象出来,Spring Kafka实际上也是调用了原生Kafka客户端的KafkaConsumer.poll()方法来获取kafka消息,然后再喂给业务过程。
6. 总结
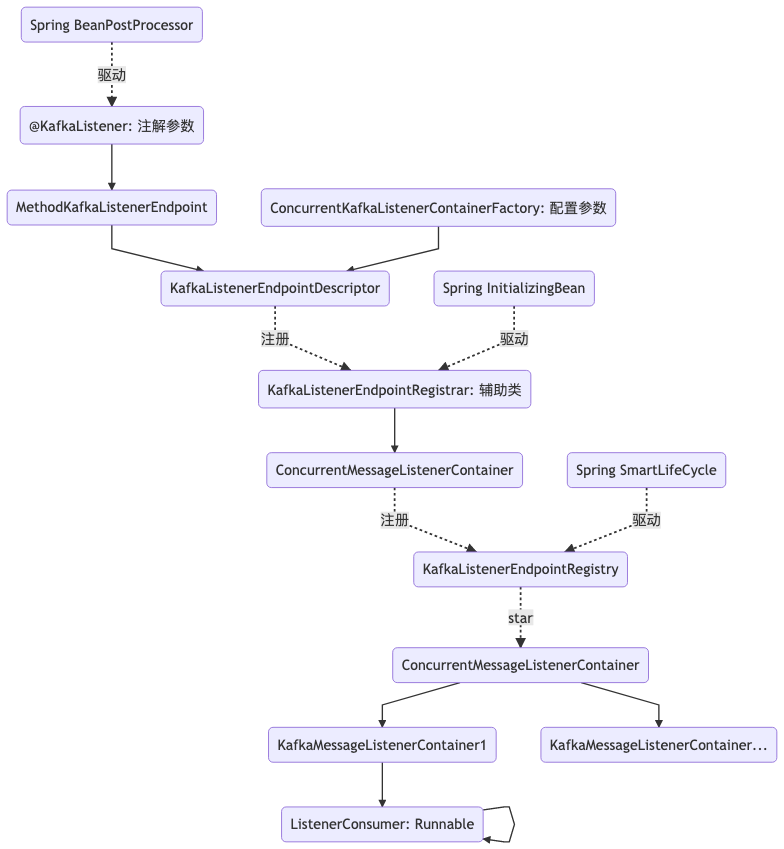
graph TD;
A("@KafkaListener: 注解参数")-->B("MethodKafkaListenerEndpoint");
B-->D;
C("ConcurrentKafkaListenerContainerFactory: 配置参数")-->D("KafkaListenerEndpointDescriptor");
D-.->|注册|E("KafkaListenerEndpointRegistrar: 辅助类");
E-->F("ConcurrentMessageListenerContainer");
F-.->|注册|G("KafkaListenerEndpointRegistry");
G-.->|start|H("ConcurrentMessageListenerContainer");
H-->I("KafkaMessageListenerContainer1");
H-->M("KafkaMessageListenerContainer...");
I-->N("ListenerConsumer: Runnable");
N-->N;
J("Spring BeanPostProcessor")-.->|驱动|A
K("Spring InitializingBean")-.->|驱动|E
L("Spring SmartLifeCycle")-.->|驱动|G
7. 有感
有时候,因为业务需要快速实现,没办法完全掌握一门框架后再下手,这就导致了代码的不可控,有些情况下,Coder会失了神,这样实现到底framework native吗?如果引入一个框架而无法榨取它的价值,那就得考虑它存在的意义了,依赖数量和复杂度肯定是正比关系。如何能榨取框架的价值?。对于我而言,从下而上的效率太低。往往买了一本《XXX实践》,还没翻到业务强相关的地方,就没时间了,坚持不下去了,然后尘封于书桌。对于Coder而言,最好的描述语言是Code,点开IDEA,“Download Sources”,看源码的过程可能会痛苦,但是啥都不会的后果会更痛苦。🏄🏻♂️